In this blog post, we sift through the complexity of multilingual content delivery, especially when not all documents are translated and available in every language.
The situation
Your technical documentation is published in multiple languages: 2, 10, even 20 or more for some of you. The easy case would be to have all documents — meaning here any piece of content such as topics, files, images, entire books, etc. — existing in every language and always in sync. But we know that the reality is far from being that simple.
Usually, your tech writing team creates content in one reference language. Let’s say English to keep it simple, because it’s the lingua franca of technical documentation and true at 90%. This could mean that even if an expert provides some content in another language, it is likely translated in English. Let’s call it the Reference Corpus.
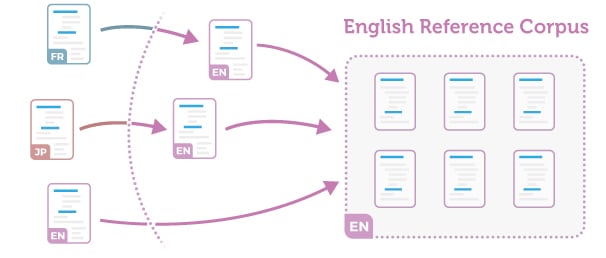
The challenge
You are a global company with some end-users who are not speaking English. Let’s say they speak Japanese and French. You have two possibilities:
- You translate everything -> “English Corpus” = “French Corpus” = “Japanese Corpus”.
Then it’s easy. You are sure that whatever language they speak, your users have access to all information. Your users read in their native language, and you can automatically set the appropriate search language based on the browser language or the user preference. - Only a subset of the entire corpus is translated (the content dedicated to end-users), and part of the documentation is not translated but available only in English (the content for experts and partners for example). Even worse, each country adds some documentation that exists only in its language (regulatory and compliance notices, local features, etc.).
The situation looks like this:
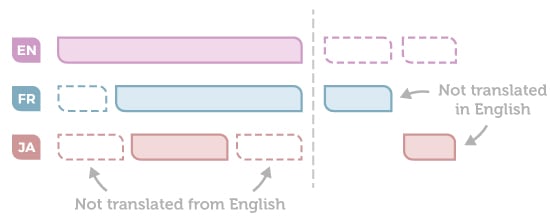
Now the question is very simple: How should your portal behave? When a user searches for information, what content blocks (see image above) should be looked upon?
Let’s keep it simple and say that our user, Jean, is French. Jean chooses the French UI. As in case 2, part but not all of your content is translated into French. Jean needs to know how to fix a component and runs a search for “X124 installation”. What should happen?
A- The search is run on all documents (En, Fr and Ja)
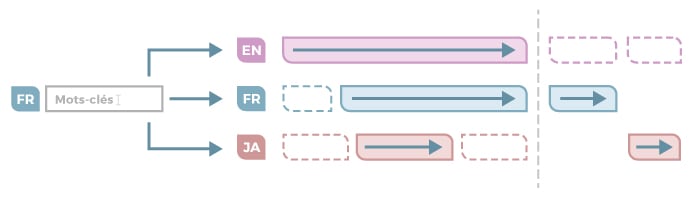
Pros:
- No risk of missing any information since, by default, each and every byte of content is included in the search.
Cons:
- Results are possibly duplicated, or even irrelevant. Keywords exist in different languages (here in Fr en En) and an ambivalent query could lead to misleading results.
- Returning results in a language a user does not understand is inappropriate. How would you feel about a page stuffed with Japanese text if you don’t read Japanese? Surfacing unnecessary and overwhelming information creates a poor and inefficient user experience. Users could refine their searches by filtering in or out desired languages. But, why not make it automatic (see next case)? (see next case).
B- The search is run in one selected language (Fr for Jean)
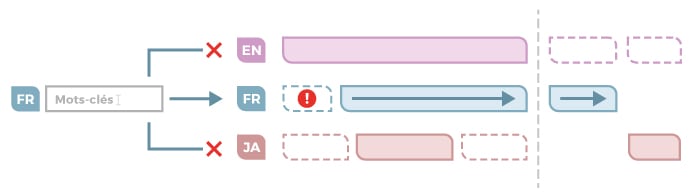
Pros:
- Consistent search results and easy user experience, as only French results are displayed.
Cons:
- Possibly missing information: Some content has not been translated into French and exists only in English, which means that some critical information relevant to the situation may be missing.
- Even worse, the search could return “0 result”, making the user believe that there is nothing to help him. And, the probability of having no search results is increased significantly.
We see that both ways of searching are causing problems. And, the intermediate approach of searching in the French and English corpus (user and reference languages) leads to the same issues described in A. Then what should we do?
It’s obvious that the search should run on a set of documentation made of the French elements plus the English elements applicable but NOT translated. Let’s call this the Full Virtual Corpus:
- Full, because it now encompasses all content relevant to a user
- Virtual, because it is made of different blocks of content from different languages
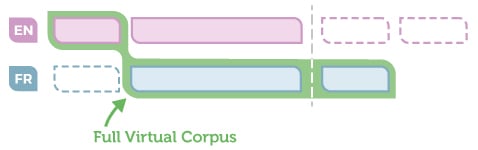
But it’s not that simple. Running a search with French keywords on English content does not make much sense, as the keywords and the content won’t match. However, we can assume that the user reads English as the choice of not translating everything was made, because this specific content is meant for people used to English (e.g. sysadmin in IT).
Then there are two ways of doing it:
- Low-tech: Execute the query on the French Corpus. Warn the user that some content may be missing and that they should also do a query with English keywords (and run the query on the English corpus, or on the English content part of the Full Virtual Corpus).

- High-tech: Automatically translate the user query and run two queries at the same time … with the initial keywords on the French subpart of the Full Virtual Corpus and the translated keywords on the English subpart.

The high-tech approach is what should be done, but it can be quite complex. How do you translate the query? Multiple solutions:
- Rely on external generic translation web services. Certainly the approach requiring the least amount of work, but it may lead to poor results, as those web services are not aware of the specificities and vocabularies of your domain and content.
- As users search with keywords and not phrases, you can provide a dictionary of terms — mixing generic dictionaries and specific dictionaries for your business term — and do word-for-word translation. This requires significant work, as you must create and maintain those dictionaries.
- Here is the trick: Those dictionaries already exist! They are the translation memories. Since part of your content has been translated, this has generated aligned dictionaries of terms and expressions. Just use it.
Important: Even if we know the language of that user (from their browser or preferences), it’s important to keep in mind that there is a difference between the UI language and the content language. The UI may be available in 10 languages, but your documentation only in 3. A German user may set their UI to German but still has to select a different “preferred language for content” if none of your documentation is available in German (as in our example). Either you declare a default fallback language for German (“if UI in German than search in English”), or the user selects it manually.
As you have read in this blog post, multilingual content delivery is not that simple. It doesn’t just mean that you must index all content. It requires understanding and technology to best match your situation. Being on the edge of dynamic content delivery, Fluid Topics already embeds the tools that you need. We continue to research and investigate with our partners specialized in translation, such as WhP, to always push the limits and make your content the cornerstone of your customer support strategy.
About The Author



