

Content-Betrieb
Wie KI das technische Schreiben verändert: Semantische Anreicherung
Semantische Anreicherung, eine in der Suchmaschinenoptimierung häufig verwendete Technik, ist ein zentraler Pfeiler bei der Erstellung KI-freundlicher Dokumentation. Zusammen mit Struktur und Metadaten helfen Semantiken Computern, wesentliche Daten zu extrahieren und komplexe Fragen zu beantworten.

Inhaltsverzeichnis
- Was ist semantische Anreicherung?
- Warum müssen wir Informationen Bedeutung geben?
- Warum Semantik und Bedeutung in der technischen Dokumentation wichtig sind
- Semantiken hinzufügen
- Anpassungen für das Computerverständnis vornehmen
- Wie Sie Semantiken auf Ihre technische Dokumentation anwenden
- Abschluss des Content Value Path
Hinweis: Dieser Blogartikel wurde aus seiner Originalversion übersetzt und kann geringfügige Abweichungen enthalten. Einige der Links in diesem Artikel führen zu Inhalten, die nur auf Englisch verfügbar sind.
Der letzte Schritt im Content Value Path – einer Lösung für die Bereitstellung von Inhalten an innovative Technologien wie KI-Anwendungen – ist die semantische Anreicherung. Die Branche der technischen Dokumentation ist mit dieser dritten Säule wahrscheinlich weniger vertraut als mit den Elementen, die wir in den ersten beiden Artikeln dieser Serie behandelt haben: Struktur und Metadaten.
Lassen Sie uns unsere Must-have-Liste der Dokumentationskomponenten vervollständigen, indem wir untersuchen, was semantische Anreicherung ist, warum sie für Dokumentation in einer KI-Welt wichtig ist und wie man Semantiken zu seinem Text hinzufügt.
Was ist semantische Anreicherung?
Semantische Anreicherung ist eine bekannte Technik, die am häufigsten in der Suchmaschinenoptimierung (SEO) für Webinhalte eingesetzt wird. Diese Technik versieht Text mit Tags, die Suchalgorithmen helfen, Informationen wie Namen von Personen oder Produkten, Daten, Mengen, Referenzen, Ereignisse und mehr eindeutig zu identifizieren und zu extrahieren.
Beim Untersuchen eines Satzes könnten beispielsweise folgende Arten relevanter Entitäten im Backend getaggt werden:

Der Quelltext kann somit angereichert werden, um Marker einzuschließen, die es Algorithmen ermöglichen, automatisch und eindeutig wesentliche Daten zu extrahieren, einen Knowledge Graph aufzubauen und auf komplexe Fragen zu antworten.

Warum müssen wir Informationen Bedeutung geben?
Bevor wir erklären, wie man Text semantisiert, lassen Sie uns aufschlüsseln, wie Informationen Bedeutung erlangen. Sie fragen sich vielleicht, haben nicht alle Informationen Bedeutung? Ja und nein. Wörter bedeuten uns etwas, weil wir Menschen mit Lebenserfahrungen sind, die es uns ermöglichen, interne abstrakte Repräsentationen aufzubauen. Dies ermöglicht es uns, Bedeutung aus Text zu extrahieren, indem wir die Wörter auf unsere internen Wissensmodelle abbilden.
Computer haben diese Lebenserfahrungen nicht und benötigen daher mehr Kontext und Unterstützung, um Informationen zu verstehen. Deshalb müssen wir Informationen beschriften und Anweisungen geben, was mit diesen Beschriftungen zu tun ist.
Nehmen wir zum Beispiel das Wort „Pfeife“. Als Menschen lesen wir dieses Wort, und unser Gehirn zaubert automatisch ein Bild hervor. Vielleicht visualisieren Sie die kleine Plastikpfeife aus dem Brettspiel Cluedo. Oder vielleicht denken Sie an eine alte Holzpfeife und riechen instinktiv den Rauch aus Erinnerungen. „Pfeife“ bedeutet jedoch nichts für einen Computer. Er sieht nur vier Buchstaben „P-f-e-i-f-e“, oder schlimmer noch, er sieht sechs Bytes in ASCII. Dies ist weit davon entfernt, Bedeutung und Handlung zu verstehen.
Hier kommt die semantische Anreicherung ins Spiel. Das folgende Beispiel zeigt, wie Google strukturierte Daten zu Bewertungen und Rezensenten zusätzlich zum Text für ein Suchergebnis anzeigt.

Wie kann Google das tun? Es liegt daran, dass der Quellinhalt (die Webseite auf wired.com) Marker und Tags enthält, die Google anzeigen, dass „9/10″ nicht nur Text ist, sondern eine Bewertung. Menschen haben solche Tags definiert, normalisiert und dokumentiert: siehe schema.org, RDFa, JSON-LD und Microdata.
Warum Semantik und Bedeutung in der technischen Dokumentation wichtig sind
Wie wirkt sich dies auf die technische Dokumentation aus? Lassen Sie uns den Prozess der semantischen Anreicherung und ihre Auswirkungen anhand eines realen Beispiels durchgehen. Der folgende Text ist ein stark bearbeitetes Beispiel von RJ Gas Appliances zur Kalibrierung eines Thermostats.
Zunächst präsentieren wir diesen Text als einfache Zeichenkette, auch wenn Autoren Informationen in der technischen Dokumentation nicht wirklich so darstellen würden.

Alle Informationen befinden sich im Absatz. Wenn diese Textauswahl alles wäre, was Sie zur Verfügung hätten, könnten Sie wahrscheinlich Ihren Thermostat kalibrieren. Die meisten Menschen würden verstehen, dass die ersten beiden Sätze eigentlich der Titel und Untertitel des Textes sind. Sie geben keine Anweisungen, sondern dienen dazu, den folgenden Text zu charakterisieren. Dann folgen die Anweisungen im Rest des Absatzes, wobei jeder Satz einen neuen Schritt umfasst.
RJ Gas Appliances teilt diese Informationen auf ihrer Website mit einer einfachen Formatierung, die sie viel leichter nachvollziehbar und verständlich macht.

In diesem Beispiel ist der Titel klar, und die Formatierung zeigt an, dass es mehrere Anweisungen gibt, basierend auf Ihren bisherigen Erfahrungen mit Aufzählungslisten. Im Grunde semantisieren Sie unbewusst den Text und geben ihm Bedeutung, indem Sie automatisch jeden Aufzählungspunkt in einen neuen Schritt verwandeln. Darüber hinaus nehmen Sie an, dass aufgelistete Schritte von oben nach unten ausgeführt werden müssen. Die größte Herausforderung besteht darin, zu verstehen, dass Sie nur einen der letzten beiden Schritte ausführen müssen, abhängig vom ersten Schritt.
Semantiken hinzufügen
Der nächste Schritt besteht darin, Semantiken und leichte Designänderungen hinzuzufügen. Die semantischen Änderungen sollten dem Benutzer helfen und sein implizites Fachwissen offenbaren. Parallel dazu heben die Designänderungen die To-do-Listen-Schritte auf weniger mehrdeutige Weise hervor.
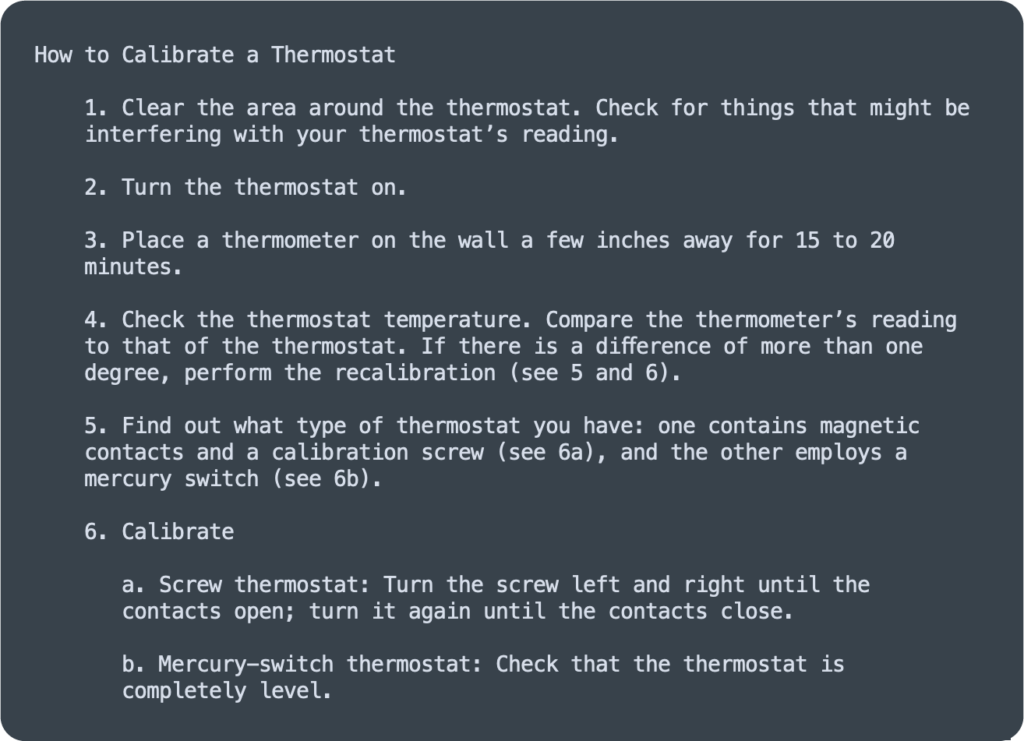
Die Nummerierung macht deutlich, dass Sie oben beginnen und sich nach unten vorarbeiten sollten, anstatt die Schritte zufällig auszuführen oder nur ein oder zwei auszuwählen. Durch das Hinzufügen von (a) und (b) in Schritt 6 fügen wir außerdem mehr Semantik für den Leser ein, um zu verstehen, dass er je nach Art des Thermostats eine der beiden Optionen wählen sollte.
Jetzt ist der Text expliziter und verlässt sich weniger auf die bisherigen Erfahrungen des Benutzers. Es fehlen jedoch noch Informationen, die einem Softwareprogramm helfen würden, ihn zu verstehen. Beispielsweise könnte ein KI-gestützter Chatbot oder virtueller Assistent wie Amazon Alexa oder Google Home mehr Kontext benötigen, um einen Benutzer durch diese Kalibrierungsschritte zu führen.
Anpassungen für das Computerverständnis vornehmen
Um das erforderliche Niveau der semantischen Anreicherung zu erreichen, müssen wir den Quelltext so taggen, dass der Computer weiß, dass sich der Inhalt auf eine Aufgabe bezieht und Schritte enthält. Da viele technische Dokumente mit strukturiertem Authoring wie DITA oder anderen XML-basierten Formaten erstellt werden, schauen wir uns an, wie Tags oder Labels mit diesen Schreibformaten aussehen würden.

Jetzt ist dies mit den Tags eindeutig eine Prozedur. Wir sehen auch, dass jede Zeile ein Schritt ist und dass Sie nur eine der letzten Anweisungen auswählen können. So sieht semantisch angereicherter Text aus. Ein Computer könnte dies aufnehmen, verstehen, worum es geht, und vorprogrammierte Einstellungen verwenden, um das „Schritt“-Tag auf hilfreiche Weise anzuzeigen. Dies könnte alles sein, von Nummern über Aufzählungspunkte bis hin zu gerätespezifischen Anweisungen, wie das Anzeigen jeweils eines Schritts, wenn der Bildschirm unter einer bestimmten Größe ist. Die Computeranweisungen könnten auch sein, jeden Schritt laut vorzulesen, wenn das Gerät ein Lautsprecher ist. Wenn das Gerät oder der Algorithmus die Modellnummer Ihres Thermostats kennt, könnte – und sollte – es die relevanten Anweisungen vorauswählen und nur diese anzeigen. Dies ist ein Kernelement der dynamischen Bereitstellung.
Schauen wir uns an, wie eine weitere Ebene der Semantik im Text aussehen könnte.

Obwohl es für einen Menschen so vielleicht schwerer zu lesen ist – die Leseschnittstelle würde die Tags jedoch verbergen und ihn als einfachen, leicht verständlichen Text darstellen – könnte ein Computer diesen Inhalt leichter nutzen, um präzise auf Fragen wie „Sagen Sie mir, wie ich einen Quecksilberschalter-Thermostat kalibriere“ zu antworten. Alles, was der Computer braucht, um einen Knowledge Graph aufzubauen oder relevante Antworten zu extrahieren, steht direkt im Inhalt, sogar ohne fortgeschrittene Sprachmodelltechnologie.
Wie Sie Semantiken auf Ihre technische Dokumentation anwenden
Das Hinzufügen relevanter Semantiken zu Text ist der letzte Schritt zur Vervollständigung unseres Content Value Path. Es sieht mühsam aus, also wie können Sie dies erreichen?
- Definieren Sie Ihre wichtigsten Anwendungsfälle: Wer sind Ihre Hauptdokumentationsnutzer? Welche Arten von Fragen könnte jede Persona stellen? Unter welchen Umständen und mit welchen Zielen könnten sie mit Ihren Inhalten interagieren?
- Nachdem Sie diese Schlüsselinformationselemente generiert haben, können Sie die Arten von Entitäten auflisten, die beschriftet werden müssen. Dies kann Produkte, Referenzen, Komponenten, Technologien, Messungen, Daten oder andere Elemente umfassen.
- Schließlich ist die wichtigste Frage: Wie gehen Sie beim Beschriften all Ihrer Inhalte vor? Müssen Sie all diese Marker manuell einfügen? Dies wäre eine überwältigende Aufgabe, insbesondere wenn Sie Tausende von Seiten an Dokumentation haben.
Hier kommt die Technologie zur Rettung. Dank maschinellen Lernens können Algorithmen die semantische Beschriftung mit hoher Präzision automatisieren. Sie benötigen nur einige Dutzend manuell getaggte Themen zum Studieren, bevor sie autonom werden. Dieser Automatisierungsschritt erfolgt typischerweise on-the-fly, während das Publishing-System alle notwendigen Dokumentationen in seinem Content-Repository sammelt.
Abschluss des Content Value Path
Struktur, Metadaten und semantische Anreicherung – dies sind die drei Elemente, die in der Dokumentation benötigt werden, um den Content Value Path zu konstruieren. Nach dem Lesen aller drei Artikel dieser Serie sind die Schritte zur Verbesserung der Inhaltserfahrung für Benutzer klar.
- Definieren Sie Ihre Anwendungsfälle und die Standardfragen, die Benutzer während ihrer Produktreisen haben.
- Verwenden Sie diese Informationen, um abzuleiten, welche Metadaten und Entitäten notwendig sind.
- Wechseln Sie zu strukturierter Dokumentation und passen Sie Ihre Content-Granularität an, um Text in Topics und Maps aufzuteilen.
- Fügen Sie Metadaten und Beschriftungsentitäten manuell zu einer repräsentativen Stichprobe Ihrer Inhalte hinzu. Verwenden Sie dann diese Elemente, um automatische Entitätsklassifizierungs- und Extraktionstools zu „trainieren“.
Für den letzten Schritt benötigen Sie ein dynamisches Publishing-Tool mit der Kapazität, die Bausteine zu integrieren und bereitzustellen, die zur Verbesserung von Inhalten erforderlich sind. Fluid Topics ist die führende KI-gestützte Content-Delivery-Plattform, die Unternehmen die Grundlage bietet, den Content Value Path zu aktivieren.
Vereinbaren Sie eine kostenlose Demo von Fluid Topics mit einem Produktexperten
 Agentische KI vs. Generative KI: Ein Leitfaden für technische Redakteure
Agentische KI vs. Generative KI: Ein Leitfaden für technische Redakteure
 Digitaler Produktpass (DPP): Was er ist und warum er wichtig ist
Digitaler Produktpass (DPP): Was er ist und warum er wichtig ist