

Content Ops
How AI is Reshaping Technical Writing: Semantic Enablement
Semantic enablement, a technique commonly used in SEO, is a key pillar in creating AI-friendly documentation. Along with structure and metadata, semantics help computers extract essential data and respond to complex questions.

Table of Contents
The last step in the Content Value Path — a solution when delivering content to innovative technologies like AI applications — is semantic enablement. The technical documentation industry is likely less familiar with this third pillar than with the elements we covered in the first two articles of this series: structure and metadata.
Let’s round out our must-have list of documentation components by exploring what semantic enablement is, why it matters for documentation in an AI world, and how to go about adding semantics to your text.
What is Semantic Enablement?
Semantic enablement is a well-known technique, most commonly used in Search Engine Optimization (SEO) for Web content. This technique labels text with tags that help search algorithms clearly identify and extract information such as names of people or products, dates, quantities, references, events, and more.
For example, when inspecting a sentence, here are some of the types of relevant entities one could tag in the backend.

Hence, the source text can be enriched to include markers that allow algorithms to automatically and unambiguously extract essential data, build a knowledge graph, and respond to complex questions.

Why Do We Need to Give Information Meaning?
Before explaining how to semanticize text, let’s break down how information takes on meaning. You may be wondering, doesn’t all information hold meaning? Yes and no. Words mean something to us because we are human beings with life experiences that allow us to build internal abstract representations. This allows us to extract meaning from text by mapping the words to your internal knowledge models.
Computers don’t have these life experiences and therefore need more context and support to understand information. Therefore, we need to label information and give instructions on what to do with those labels.
Take the word “pipe” for example. As humans we read this word, and our brains automatically conjure a picture. Maybe you visualize the small plastic pipe from the board game Clue. Or maybe you think of an old wooden pipe, instinctively smelling the smoke from memories. However, “pipe” means nothing to a computer. It just sees four letters “p-i-p-e”, or worse, it sees four bytes in ASCII, #70697065. This is far from understanding meaning and action.
This is where semantic enablement comes in. The example below shows how Google displays structured data around ratings and reviewers in addition to text for a search result.

How can Google do this? It is because the source content (the web page on wired.com) includes markers and tags that indicate to Google that “9/10” is not just text, but a rating score. Humans have defined, normalized, and documented such tags: see schema.org, RDFa, JSON-LD and Microdata.
Why Semantics and Meaning Matter in Technical Documentation
How does this impact technical documentation? Let’s walk through the process of semantic enablement and its impact with a real example. The text below is a heavily edited sample from RJ Gas Appliances on how to calibrate a thermostat.
First, let’s present this text as a simple string of text, even if authors wouldn’t actually present information this way in technical documentation.

All of the information is in the paragraph. If this text selection was all you had available, you could probably calibrate your thermostat. Most people would understand that the first two sentences are actually the title and subtitle of the text. They don’t provide instructions but serve to characterize the text that follows. Then, the rest of the paragraph is instructions, with each sentence comprising a new step.
RJ Gas Appliances shares this information on their website with some simple formatting that makes it much easier to follow and understand.

In this example, the title is clear, and the formatting indicates that there are multiple instructions, based on your past experiences with bullet point lists. Basically, you’re unconsciously semanticizing the text and giving it meaning by automatically turning each bullet point into a new step. Moreover, you assume that listed steps must be executed from top to bottom. The biggest challenge is to understand that you only have to complete one of the last two steps depending on the first step.
Adding Semantics
The next step is to add semantics and slight design changes. The semantic changes should help the user and reveal their implicit expertise. In parallel, the design changes highlight the to-do-list steps in a less ambiguous way.
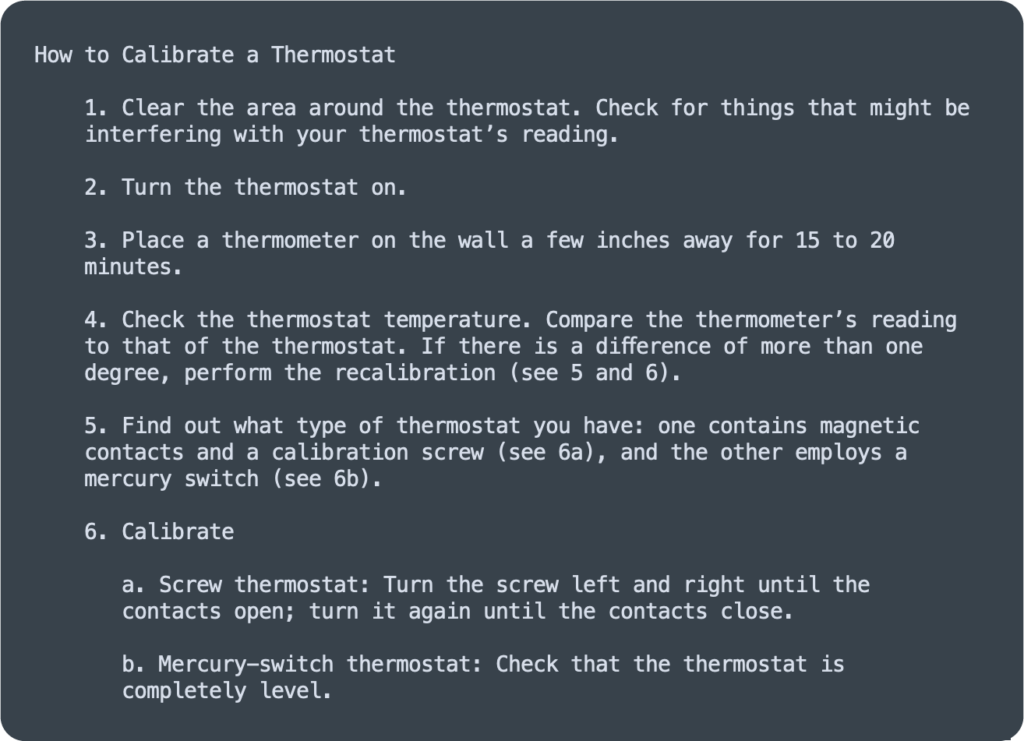
The numbering makes it clear that you should start at the top and work your way down, rather than doing the steps at random, or picking just one or two. Additionally, by adding the (a) and (b) in step 6, we insert more semantics for the reader to understand that they should pick one or the other, depending on what kind of thermostat they have.
Now, the text is more explicit and relies less on the user’s past experiences. However, it still lacks information that would help a software program understand it. For example, an AI-enabled chatbot or virtual assistant like Amazon Alexa or Google Home may need more context to guide a user through these calibration steps.
Making Adjustments for Computer Understanding
To reach the necessary level of semantic enablement, we have to tag the source text so the computer knows the content refers to a task and includes steps. Since many technical documents are prepared using structured authoring like DITA or other XML-based formats, let’s see what tags or labels would look like with these writing formats.

Now, with the tags, this is clearly a procedure. We also see that each line is a step and that you can only select one of the final instructions. This is what semantically enhanced text looks like. A computer could ingest this, understand what it’s about, and use preprogrammed settings to display the “step” tag in a helpful way. This could be anything from numbers to bullet points or include device-specific instructions like displaying one step at a time if the screen is under a certain size. The computer instructions could also be to read each step aloud if the device is a speaker. If the device or algorithm knows your thermostat’s model number, it could — and should — preselect and only display the relevant instructions. This is a core element of dynamic delivery.
Make the Switch to Dynamic Content

Let’s look at what one more layer of semantics could look like in the text.

While it may be harder for a human to read like this, — although, the reading interface would hide the tags and render it as simple, easy to grasp text — a computer could leverage this content more easily to accurately respond to questions such as “Tell me how to calibrate a mercury switch thermostat”. Everything the computer needs to build a knowledge graph or extract relevant responses is directly in the content, even without advanced language model technology.
How to Apply Semantics to your
Technical Documentation
Adding relevant semantics to text is the last step to complete our Content Value Path. It looks tedious, so how can you accomplish this?
- Define your core use cases: Who are your main documentation users? What kinds of questions might each persona ask? In which circumstances and with which objectives might they interact with your content?
- After generating these key information elements, you will be able to list the types of entities that must be labeled. This may include products, references, components, technologies, measurements, dates, or other elements.
- Finally, the most important question is: how do you go about labeling all your content? Will you have to insert all these markers manually? This would be an overwhelming task, especially if you have thousands of pages of documentation.
Here, technology comes to the rescue. Thanks to machine learning, algorithms can automate semantic labeling with high precision. They only need a few dozen manually tagged topics to study before becoming autonomous. This automation step typically happens on the fly as the publishing system gathers all necessary documentation into its content repository.
Concluding the Content Value Path
Structure, metadata and semantic enablement — these are the three elements needed in documentation to construct the Content Value Path. After reading all three articles in this series, the steps towards enhancing the user content experience are clear.
- Define your use cases and the standard questions users have during their product journeys.
- Use this information to deduce which metadata and entities are necessary.
- Switch to structured documentation and adapt your content granularity to break text into topics and maps.
- Manually add metadata and labeling entities to a representative sample of your content. Then, use these elements to “teach” automatic entity classification and extraction tools.
For the final step, you’ll need a dynamic publishing tool with the capacity to integrate and provide the building blocks needed to enhance content. Fluid Topics is the leading AI-powered content delivery platform that provides the basis for companies to activate the Content Value Path.
Schedule a free demo of Fluid Topics with a product expert

